Getting Started with Hadoop
In this article we will learn introduction to Hadoop and its ecosystem.

I am a Tech Enthusiast having 13+ years of experience in 𝐈𝐓 as a 𝐂𝐨𝐧𝐬𝐮𝐥𝐭𝐚𝐧𝐭, 𝐂𝐨𝐫𝐩𝐨𝐫𝐚𝐭𝐞 𝐓𝐫𝐚𝐢𝐧𝐞𝐫, 𝐌𝐞𝐧𝐭𝐨𝐫, with 12+ years in training and mentoring in 𝐒𝐨𝐟𝐭𝐰𝐚𝐫𝐞 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠, 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠, 𝐓𝐞𝐬𝐭 𝐀𝐮𝐭𝐨𝐦𝐚𝐭𝐢𝐨𝐧 𝐚𝐧𝐝 𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞. I have 𝒕𝒓𝒂𝒊𝒏𝒆𝒅 𝒎𝒐𝒓𝒆 𝒕𝒉𝒂𝒏 10,000+ 𝑰𝑻 𝑷𝒓𝒐𝒇𝒆𝒔𝒔𝒊𝒐𝒏𝒂𝒍𝒔 and 𝒄𝒐𝒏𝒅𝒖𝒄𝒕𝒆𝒅 𝒎𝒐𝒓𝒆 𝒕𝒉𝒂𝒏 500+ 𝒕𝒓𝒂𝒊𝒏𝒊𝒏𝒈 𝒔𝒆𝒔𝒔𝒊𝒐𝒏𝒔 in the areas of 𝐒𝐨𝐟𝐭𝐰𝐚𝐫𝐞 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭, 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠, 𝐂𝐥𝐨𝐮𝐝, 𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬, 𝐃𝐚𝐭𝐚 𝐕𝐢𝐬𝐮𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧𝐬, 𝐀𝐫𝐭𝐢𝐟𝐢𝐜𝐢𝐚𝐥 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 𝐚𝐧𝐝 𝐌𝐚𝐜𝐡𝐢𝐧𝐞 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠. I am interested in 𝐰𝐫𝐢𝐭𝐢𝐧𝐠 𝐛𝐥𝐨𝐠𝐬, 𝐬𝐡𝐚𝐫𝐢𝐧𝐠 𝐭𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥 𝐤𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞, 𝐬𝐨𝐥𝐯𝐢𝐧𝐠 𝐭𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥 𝐢𝐬𝐬𝐮𝐞𝐬, 𝐫𝐞𝐚𝐝𝐢𝐧𝐠 𝐚𝐧𝐝 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 new subjects.
What is Hadoop
Apache Hadoop is an open-source software, Scalable, and Fault-tolerant framework written in Java which is used for storing and processing Big Data in a distributed manner on large clusters of computers.
Components of Hadoop
Hadoop consists of three main components
Hadoop Distributed File System (HDFS) - It is a Storage Layer
Map Reduce - It is a Processing Layer
YARN - It is a Resource Management Layer

Hadoop Daemons
To support these components Hadoop provides you 5 daemon services
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager
History of Hadoop
The Hadoop was started by Doug Cutting and Mike Cafarella in 2002. Its origin was the Google File System paper, published by Google.
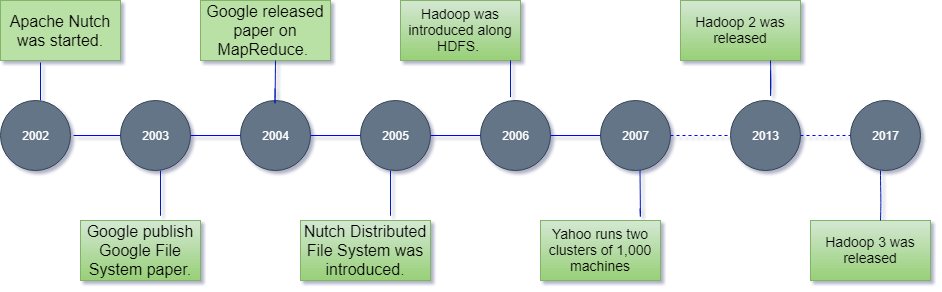
Let’s focus on the history of Hadoop in the following steps: -
In 2002, Doug Cutting and Mike Cafarella started to work on a project, Apache Nutch. It is an open source web crawler software project.
While working on Apache Nutch, they were dealing with big data. To store that data they have to spend a lot of costs which becomes the consequence of that project. This problem becomes one of the important reason for the emergence of Hadoop.
In 2003, Google introduced a file system known as GFS (Google file system). It is a proprietary distributed file system developed to provide efficient access to data.
In 2004, Google released a white paper on Map Reduce. This technique simplifies the data processing on large clusters.
In 2005, Doug Cutting and Mike Cafarella introduced a new file system known as NDFS (Nutch Distributed File System). This file system also includes Map reduce.
In 2006, Doug Cutting quit Google and joined Yahoo. On the basis of the Nutch project, Dough Cutting introduces a new project Hadoop with a file system known as HDFS (Hadoop Distributed File System). Hadoop first version 0.1.0 released in this year.
Doug Cutting gave named his project Hadoop after his son’s toy elephant.
In 2007, Yahoo runs two clusters of 1000 machines.
In 2008, Hadoop became the fastest system to sort 1 terabyte of data on a 900 node cluster within 209 seconds.
In 2013, Hadoop 2.2 was released.


