The Delta Lake Advantage

I am a Tech Enthusiast having 13+ years of experience in 𝐈𝐓 as a 𝐂𝐨𝐧𝐬𝐮𝐥𝐭𝐚𝐧𝐭, 𝐂𝐨𝐫𝐩𝐨𝐫𝐚𝐭𝐞 𝐓𝐫𝐚𝐢𝐧𝐞𝐫, 𝐌𝐞𝐧𝐭𝐨𝐫, with 12+ years in training and mentoring in 𝐒𝐨𝐟𝐭𝐰𝐚𝐫𝐞 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠, 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠, 𝐓𝐞𝐬𝐭 𝐀𝐮𝐭𝐨𝐦𝐚𝐭𝐢𝐨𝐧 𝐚𝐧𝐝 𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞. I have 𝒕𝒓𝒂𝒊𝒏𝒆𝒅 𝒎𝒐𝒓𝒆 𝒕𝒉𝒂𝒏 10,000+ 𝑰𝑻 𝑷𝒓𝒐𝒇𝒆𝒔𝒔𝒊𝒐𝒏𝒂𝒍𝒔 and 𝒄𝒐𝒏𝒅𝒖𝒄𝒕𝒆𝒅 𝒎𝒐𝒓𝒆 𝒕𝒉𝒂𝒏 500+ 𝒕𝒓𝒂𝒊𝒏𝒊𝒏𝒈 𝒔𝒆𝒔𝒔𝒊𝒐𝒏𝒔 in the areas of 𝐒𝐨𝐟𝐭𝐰𝐚𝐫𝐞 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭, 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠, 𝐂𝐥𝐨𝐮𝐝, 𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬, 𝐃𝐚𝐭𝐚 𝐕𝐢𝐬𝐮𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧𝐬, 𝐀𝐫𝐭𝐢𝐟𝐢𝐜𝐢𝐚𝐥 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 𝐚𝐧𝐝 𝐌𝐚𝐜𝐡𝐢𝐧𝐞 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠. I am interested in 𝐰𝐫𝐢𝐭𝐢𝐧𝐠 𝐛𝐥𝐨𝐠𝐬, 𝐬𝐡𝐚𝐫𝐢𝐧𝐠 𝐭𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥 𝐤𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞, 𝐬𝐨𝐥𝐯𝐢𝐧𝐠 𝐭𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥 𝐢𝐬𝐬𝐮𝐞𝐬, 𝐫𝐞𝐚𝐝𝐢𝐧𝐠 𝐚𝐧𝐝 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 new subjects.
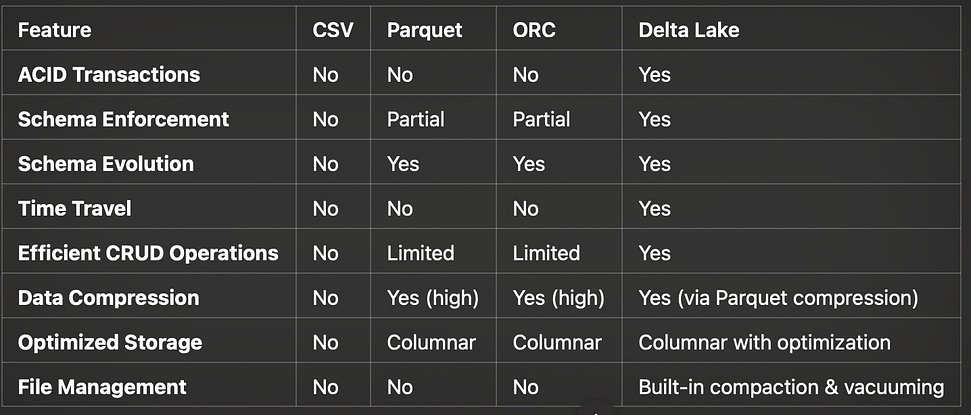
Delta Lake extends the capabilities of formats like Parquet by adding essential features for modern data lakes, particularly when handling mutable datasets or large volumes of data with frequent updates.
1. ACID Transactions:
Delta Lake supports atomicity, consistency, isolation, and durability (ACID) properties. This means data is protected from partial updates and inconsistencies, making it reliable for complex workflows that require data accuracy.
ACID compliance is critical in multi-user environments where data integrity is essential, such as in e-commerce, finance, and healthcare industries.
2. Schema Enforcement and Evolution:
Delta Lake allows for schema enforcement, preventing errors caused by incompatible data types or structure changes, a common issue in CSV or Parquet formats.
Schema evolution allows users to add, modify, or remove columns as requirements change, without breaking existing workflows.
3. Time Travel and Versioning:
Delta Lake supports time travel, enabling users to query historical versions of data, a feature that is especially valuable for audit trails, debugging, and analytical comparisons over time.
Unlike Parquet or ORC, Delta Lake allows users to access previous snapshots of data directly, providing a native solution for versioned data.
4. Efficient CRUD Operations:
Delta Lake optimizes for fast, scalable CREATE, READ, UPDATE, and DELETE (CRUD) operations, which are challenging with traditional formats.
Delta Lake’s MERGE capability makes upserts seamless, ideal for applications like real-time data feeds or slowly changing dimensions.
5. Data Optimization with Compaction and Vacuuming:
Delta Lake includes built-in commands like OPTIMIZE for file compaction and VACUUM to remove old files, reducing storage costs and improving query performance.
This addresses the common “small files” problem in big data environments, improving read efficiency and making storage more manageable over time.
6. Compatibility and Interoperability:
- Delta Lake is built on top of the Parquet format, ensuring compatibility with existing tools that read Parquet files. This allows users to transition to Delta Lake without having to overhaul their data processing pipeline.
Comparing Delta Lake with Other Formats